|
|
|
Computer Vision & Human Tracking Virtual Reality & Augmented Reality Sport Video Analysis & Traffic Surveillance |
電腦視覺 & 人物追蹤 虛擬實境 & 擴增實境 運動分析 & 交通監視 視覺式介面 & 影像式描繪 機器導航 & 數位學習 全景影片 & 虛擬導覽 |

Virtual Tour for Smart Guide & Language Learning
This project aims to build VR&AR tour guide with gesture interaction for eastern Taiwan. In the first year, we plan to develop VR tour guide App with panorama video based on Google Cardboard platform. In the second year, we propose to build VR tour guide experience station with 3D reconstruction based on HTC Vive platform. In the third year, we will construct AR tour guide experience station with gesture interaction based on Microsoft HoloLens platform.

Maritime USV Obstacle Detection
The goal is to perform obstacle detection for the maritime domain, specifically for use in unmanned surface vehicles (USV). The maritime domain
poses several unique challenges such as water texture, lighting condition, object type/size variation, limited hardware, and real-time requirement. Our submission based on YOLOv7 with modified computational block was awarded the third place in IEEE WACV MaCVi challenge in 2023.

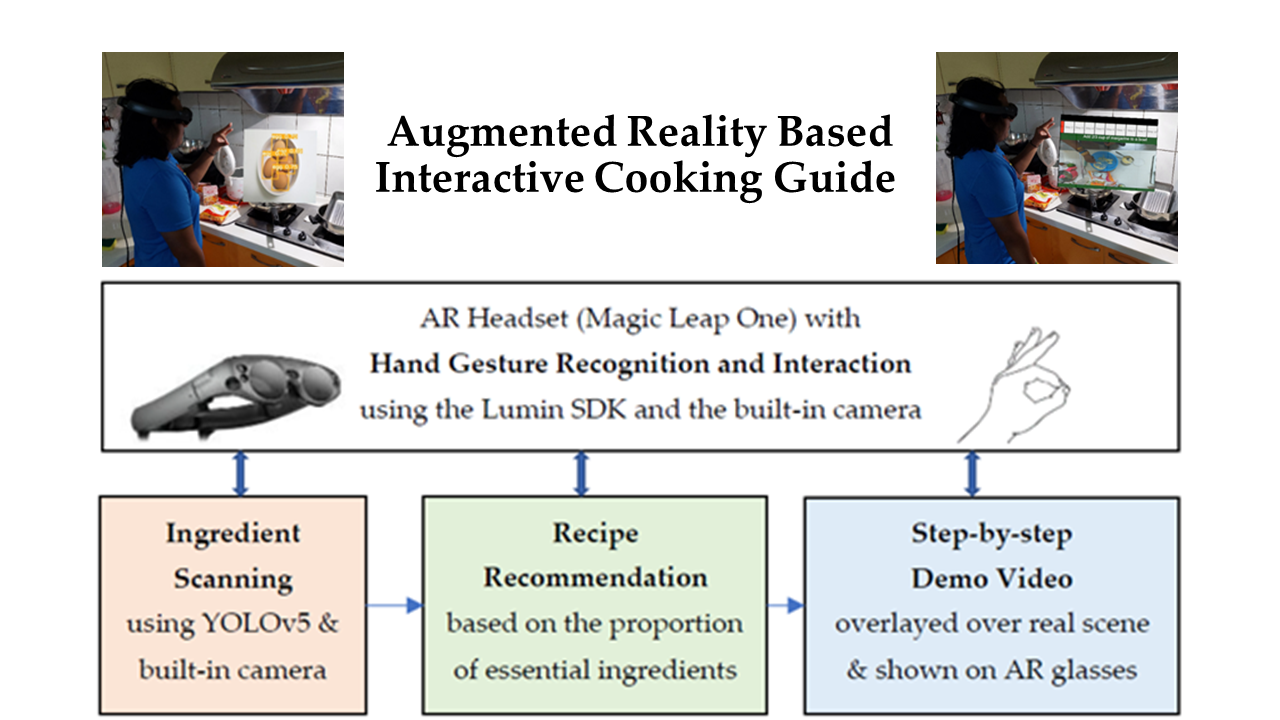
Augmented Reality Based Interactive Cooking Guide
Cooking at home is a critical survival skill. We propose a new cooking assistance system in which a user only needs to wear an all-in-one augmented reality (AR) headset without having to install any external sensors or devices in the kitchen. Utilizing the built-in camera and cutting-edge computer vision (CV) technology, the user can direct the AR headset to recognize available food ingredients by simply looking at them. Based on the types of the recognized food ingredients, suitable recipes are suggested accordingly. A step-by-step video tutorial providing details of the selected recipe is then displayed with the AR glasses. The user can conveniently interact with the proposed system using eight kinds of natural hand gestures without needing to touch any devices throughout the entire cooking process. Compared with the deep learning models ResNet and ResNeXt, experimental results show that the YOLOv5 achieves lower accuracy for ingredient recognition, but it can locate and classify multiple ingredients in one shot and make the scanning process easier for users.
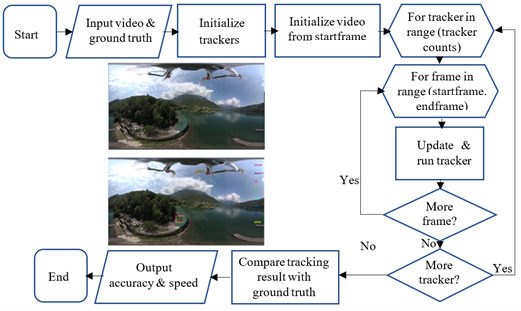
Comparison of Tracking Techniques on 360-Degree Videos
With the availability of 360-degree cameras, 360-degree videos have become popular recently. To attach a virtual tag on a physical object in 360-degree videos for augmented reality applications, automatic object tracking is required so the virtual tag can follow its corresponding physical object in 360-degree videos. Relative to ordinary videos, 360-degree videos in an equirectangular format have special characteristics such as viewpoint change, occlusion, deformation, lighting change, scale change, and camera shakiness. Tracking algorithms designed for ordinary videos may not work well on 360-degree videos. Therefore, we thoroughly evaluate the performance of eight modern trackers in terms of accuracy and speed on 360-degree videos.
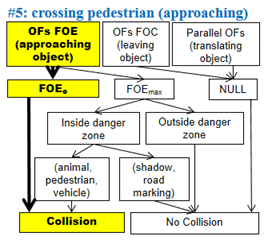
On-road Collision Warning Based on Multiple FOE
Segmentation using a Dashboard Camera
Numerous accidents can be avoided if drivers
are alerted just a few seconds before a collision. We explore the possibility
of a visual collision-warning system solely using a single dashboard camera
that is currently widely available and easy to install. Existing vision-based
collision warning systems focus on detecting specific targets, such as
pedestrians, vehicles, and bicycles, based on statistical models trained in
advance. Instead of relying on these prior models, the proposed system aims to
detect the general motion patterns of any approaching object. Considering the
fact that all motion vectors of projecting points on an approaching object
diverge from a point called focus of expansion (FOE), we construct a
cascade-like decision tree to filter out false detections in the earliest possible
stage and develop a multiple FOE segmentation algorithm to classify optical
flows based on the FOEs of individual objects. Further analysis is performed on
objects in a high risk area, called the danger zone.

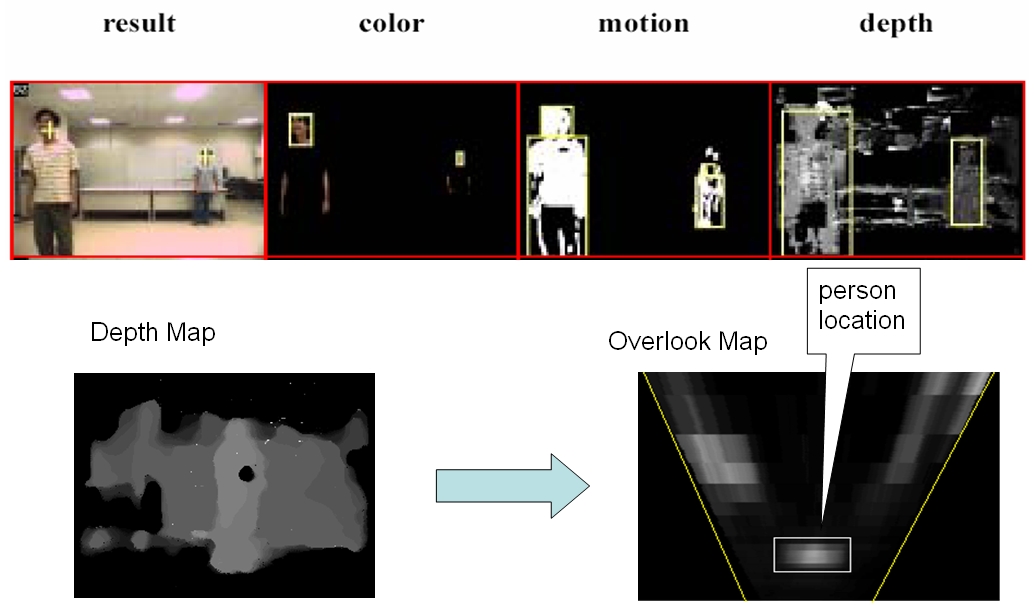
Appearance-based Multimodal Human Tracking and
Identification
One of
the fundamental problems to realize the power of smart home services is how to detect,
track, and identify people at home. We model and record multi-view faces,
full-body colors and shapes of family members in an appearance database by
using two Kinects located at a home’s entrance. Then the Kinects and another set of color cameras installed in other
parts of the house are used to
detect, track, and identify people by matching the captured color images with
the registered templates in the appearance database. People are detected
and tracked by multisensor fusion (Kinects and color cameras) using a Kalman
filter that can handle duplicate or partial measurements. People are identified
by multimodal fusion (face, body appearance, and silhouette) using a
track-based majority voting. Moreover, the appearance-based human detection,
tracking, and identification modules can cooperate
seamlessly and benefit from each other.
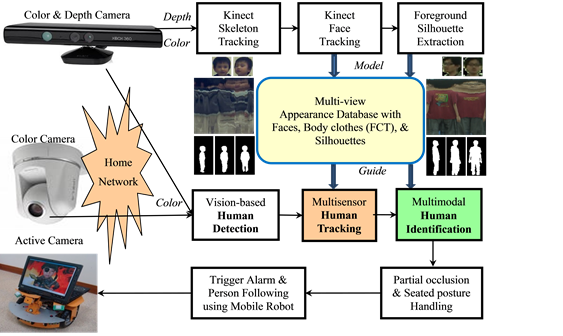
Fall Risk Assessment and Early-Warning for Toddler
Behaviors at Home
Accidental falls are the major cause of serious
injuries in toddlers, with most of these falls
happening at home. Instead of providing immediate fall detection based on short-term
observations, we propose an early-warning childcare system to monitor
fall-prone behaviors of toddlers at home. Using 3D human
skeleton tracking and floor plane detection based on depth images captured by a
Kinect system, eight fall-prone behavioral modules of toddlers are developed
and organized according to four essential criteria: posture, motion, balance, and
altitude. The final fall risk assessment is generated by a multi-modal fusion
using either a weighted mean thresholding or a support vector machine (SVM)
classification.
Virtual English Classroom
with Augmented Reality (VECAR)
The physical-virtual immersion and
real-time interaction play an essential role in cultural and language learning.
Augmented reality (AR) technology can be used to seamlessly merge virtual
objects with real-world images to realize immersions. Additionally, computer
vision (CV) technology can recognize free-hand gestures from live images to
enable intuitive interactions. Therefore, we incorporate the latest AR and CV
algorithms into a Virtual English Classroom, called VECAR, to promote immersive
and interactive language learning. By wearing a pair of mobile computing
glasses, users can interact with virtual contents in a three-dimensional space
by using intuitive free-hand gestures.

Note-Taking for 3D Curricular Contents using Markerless
Augmented Reality
For e-Learning with 3D interactive
curricular contents, an ideal note-taking approach should be intuitive and tightly-coupled
with the curricular contents. Particularly, augmented reality technology is
capable of displaying virtual contents in real-life images. Combining
head-mounted displays with cameras and wearable computers, AR provides chances
and challenges to improve note-taking for situated learning in contextual
surroundings. We propose an AR-based note-taking system tailored for 3D
curricular contents. A learner can take notes on a physical tabletop by finger
writing, manipulate curricular contents using hand gestures, and embed the
complete notes in the corresponding contents in a 3D space.

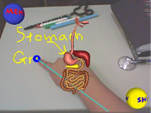

Multi-perspective
Interactive Displays using Virtual Showcases
We
propose a virtual showcase to present virtual models in a real environment. In
addition, learners interact with the virtual models of earth science materials
by combining multiple user perspectives and augmented reality display
technologies. Learners control and watch the stereoscopic virtual learning
materials through head movements and hand gestures. According to our
experiments, the virtual showcase is effective in enhancing learners’ interest
and efficiency in the learning process.

AR-based Surface Texture Replacement
We propose a texture replacement system based on AR markers to find contour of a surface object and paste new texture inside the detected contour naturally. The proposed system can analysis input images, detect contours of target surface, and apply new material to the target surface realistically. The proposed technology can be widely used on digital image/video post-production and interior design.

An Interactive 3D Input Device: 3D AR Pen
Augmented Reality (AR) technology is ideal for creating a more natural and intuitive Human-Computer-Interface (HCI). It mixes up real scenes and virtual objects, and brings a brand new experience to the users. Many new applications require 3D user control. However, most input devices used today (like mouse, stylus, and multi-touch screen) only enable 2D data input. We try to combine a cube with AR markers and a pen with a button, a LED, and a scrollbar to construct a 3D AR pen. The proposed 3D AR pen is designed for users to create and manipulate 3D contents easily and reliably. We present some possible applications that are easy to operate with the proposed 3D AR Pen such as 3D drawing, 3D carving, and 3D interface.

Facial Expression Recognition for Learning Status Analysis
Facial expression provides an important hint for teachers to know the learning status of students. Thus, expression analysis is valuable not only in Human-Computer Interface but also in e-Learning. The goal of this research is to analyze nonverbal facial expressions to discover learning status of students in distance education. The Hidden Markov Model (HMM) estimated probabilities of six expressions (Blink, Wrinkle, Shake, Nod, Yawn, and Talk) are combined into a six-dimensional vector. Gaussian Mixture Model (GMM) is applied to evaluate three learning scores including understanding, interaction, and consciousness. These scores reflect the learning status of a student and are helpful to not only teachers but also students for improving teaching and learning.
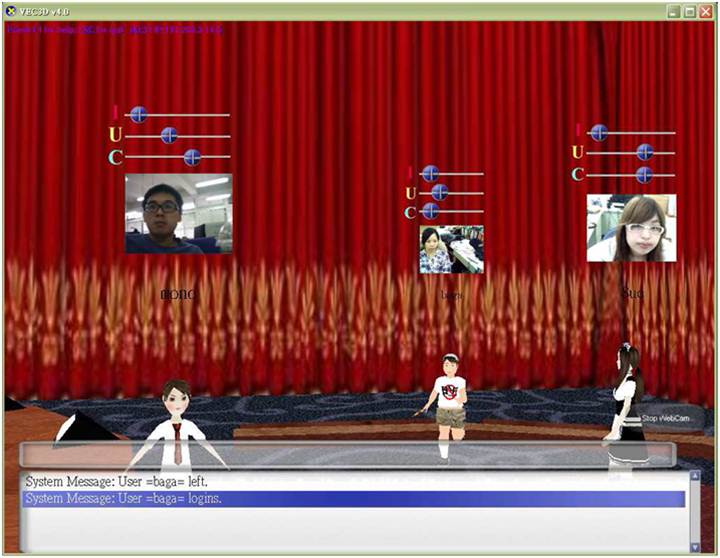
3D Virtual English Classroom (VEC3D)
We design a campus-like virtual reality that provides an authentic contact for English learners in Taiwan. The project is significant in the visualized and audio representation, synchronous communication, and real-time interaction inspiring students to take part in the learning environment. VEC3D allows students to create their virtual rooms with 3D graphics, choose various avatars to express their identity visually, and move freely in the virtual world. When students enter the virtual world, they see a mentoring avatar, and their on-line anonymous partners. They are also allowed to see and chat with each other via real-time text and voice in virtual spaces such as student center, classroom, multimedia lab, cafeteria or individual room.

Virtual Talking Head Driven by either Video or Voice
Animation of a talking head based on 3D model usually lack realism. Thus, we try to animate a virtual talking head using technique of image-based rendering (IBR). An audio/visual mapping mechanism is proposed for talking face driven by input voice. A lip detection algorithm is designed for talking face animated by captured video.
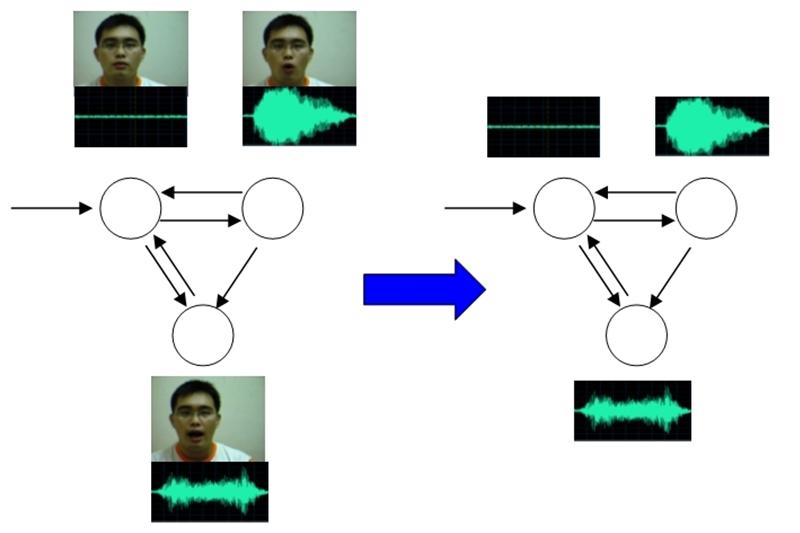
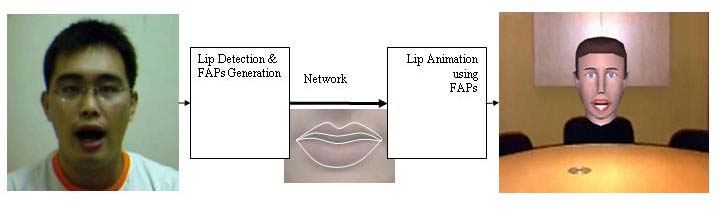
Lip Contour Extraction
We construct a lip contour extraction system based on color, shape, and motion features. The facial animation parameters are extracted to animate a virtual talking head on remote side. The proposed solutions can be applied to e-learning, teleconferencing, and other applications.
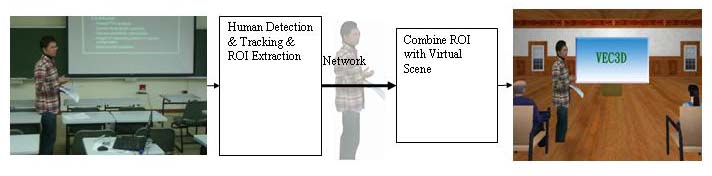
Adaptive Multi-part People Detection, Segmentation & Tracking
E-Learning and teleconferencing are important and popular applications of information technology these days. The common place of these applications is the requirement to broadcast image sequence over network with limited bandwidth. A vision-based human feature detection/tracking system can effectively reduce the network traffic by transmitting only the region of interest (ROI) or the feature parameters instead of the whole image.
Guitar Tutoring System based on Markerless Augmented Reality
We propose a real-time guitar AR tutoring system that recognizes chord fingerings based on left-hand postures and determines rhythm riffs based on right-hand optical flows and voice analysis. Visual hints are overlaied on the captured video in real-time so learners can follow the instructions intuitively.

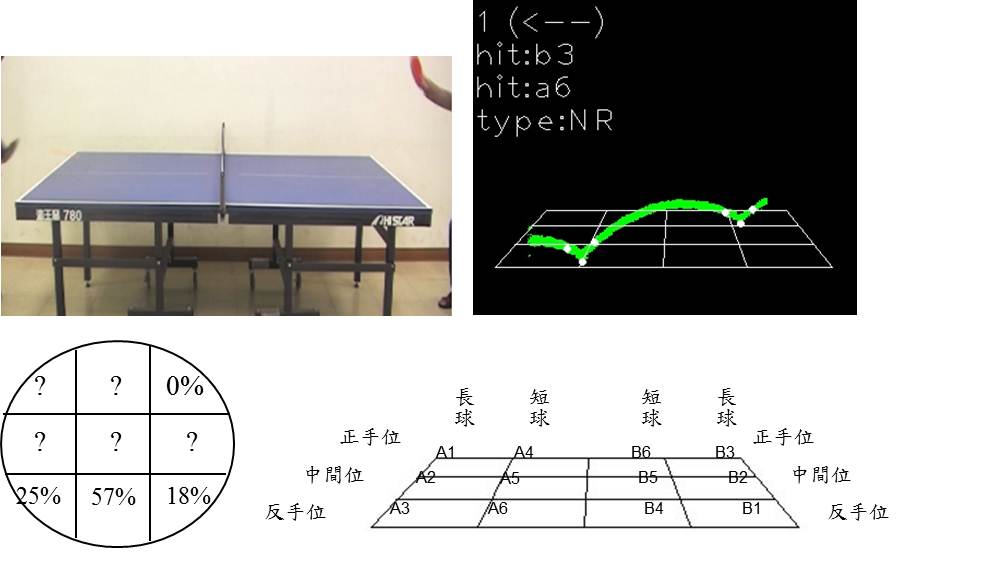
Vision-based Trajectory Analysis for Table Tennis Game
We present a vision-based system for table tennis for game recording and analysis. We keep track of the information of the trajectories, hit positions and spin directions, to describe every point in a game. We also present how to record the content of a game and how to analyze the strategy of a game. The results of our system can provide hints for players, coaches, and audiences for their reference.
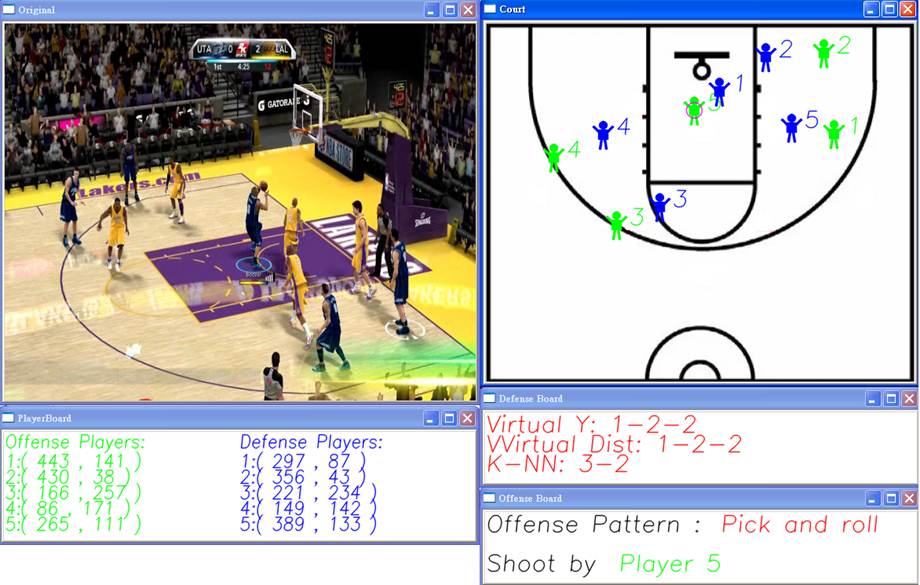
Visual Analysis for Offense-Defense Patterns in Basketball Game
We analyze the relative 2D locations of players, basketball, and basket to determine offense and defense patterns in a basketball video captured in a fixed view point. With the help of the proposed system, audiences can realize the game matching strategy and more deep information that are missing in current basketball game broadcasting.
Pitching Type Recognition for Baseball Game
We propose a baseball analysis system that recognizes pitching types by recovering baseball trajectory from baseball broadcast videos. The proposed system can help audiences recognize pitching types in baseball broadcast videos. It is also useful for players to discover pitching styles of pitchers to develop countering batting tactics.

Multi-Viewpoints Human Action Analysis
Human action analysis and recognition is critical for many vision-based applications such as video surveillance, human-computer interface, video indexing and searching. We propose to analyze and recognize human action in an image sequence by extracting features of interesting points that are detected from both spatial and temporal domain.
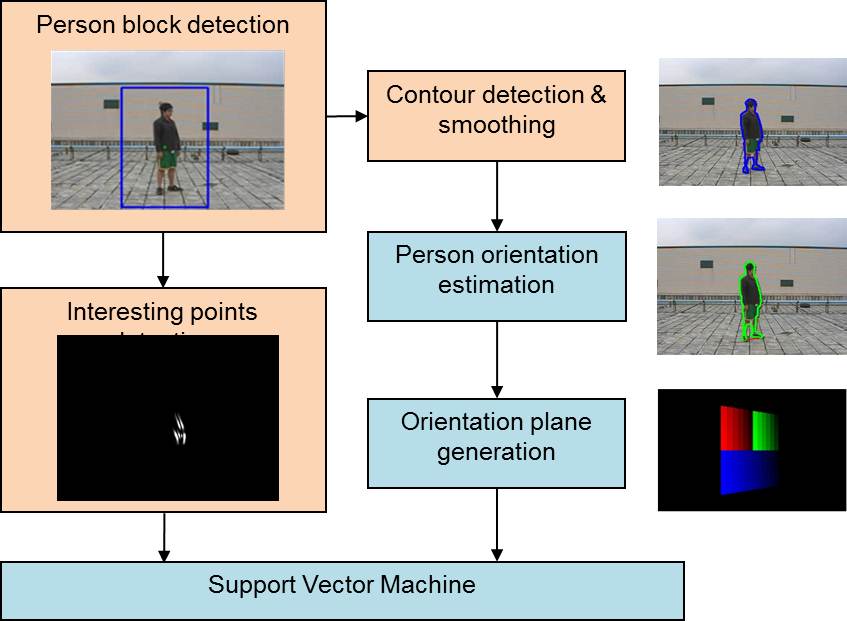
A Multimodal Fusion System for Human Detection and Tracking
A person detection system considering only a single feature tends to be unstable in changeful environments. We design a multimodal fusion system that can detect and track people in an accurate, robust, fast and flexible manner. Each detection module considering a single feature can operate independently, and the outputs of individual modules are integrated together and tracked by a Kalman filter, then the result of the integration is feedback into each individual model to update their parameters to suppress false alarms and refine the detection.
Moving Cast Shadow
Detection
Cast shadows of moving objects often cause problems to many applications such as video surveillance, obstacle tracking and Intelligent Transportation Systems (ITS). We design an segmentation algorithm considering color, shading, texture, neighborhoods and temporal consistency to detect and remove shadows in either static or dynamic scenes.

Vision-based Mobile Robot Navigation
We utilize a mobile robot equipped with an active camera and a laptop computer to serve in digital home. One of the fundamental obstacles to realizing the power of autonomous robots is the difficulty to sense its environment. An intelligent robot should be able to answer a few important questions: where the robot is, what/who is in the environment, what to do, and how to do it. We propose to find the answers of these questions with vision-based techniques. The possible applications of autonomous robots in intelligent digital home are home security, entertainment, e-learning, and home nursing.

Vision-based Traffic Surveillance
Vision-based traffic surveillance plays an important role in traffic management. However, outdoor illumination, the cast shadows, and vehicle variations often create problems in the process of video analysis . Thus, we propose a real-time traffic monitoring system that analyzes the spatial-temporal profiles to reliably estimate the traffic flow/speed, and classify the vehicle types at the same time.

Virtual
Reality Navigation using Image-Based Rendering (IBR) Techniques
We design a visualization and presentation system that can construct a virtual space based on image based rendering (IBR) techniques, in that new images can be generated from other captured images rather than from geometric primitives. The panorama technology enables users to look around a virtual scene from arbitrary viewing angles. The object movie technology enables users to look at a virtual object from arbitrary viewpoints. We extend these technologies and investigate the possibilities of stereo panorama and active object movie.
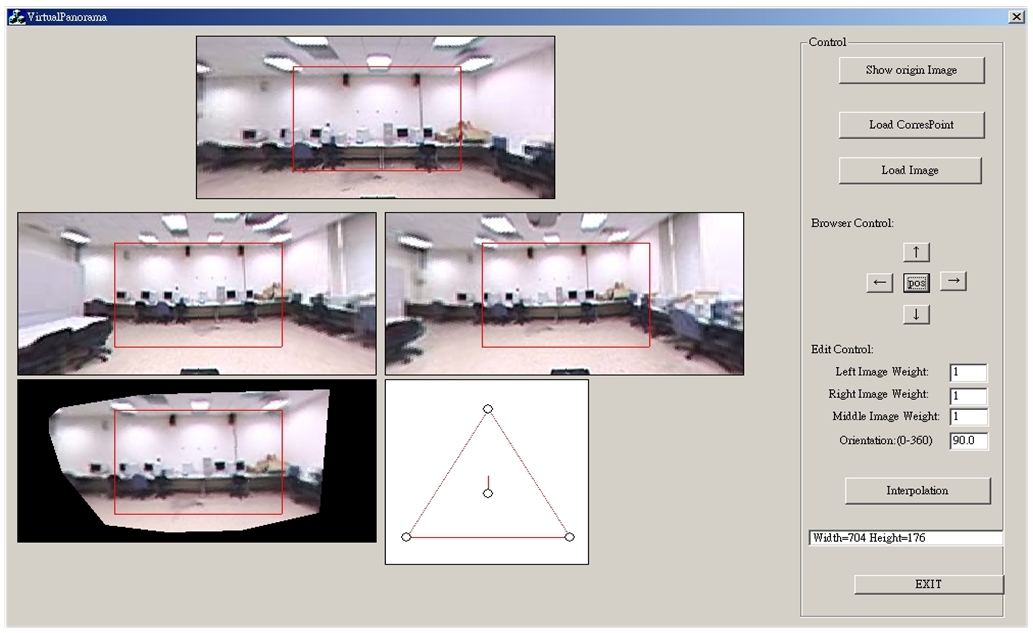
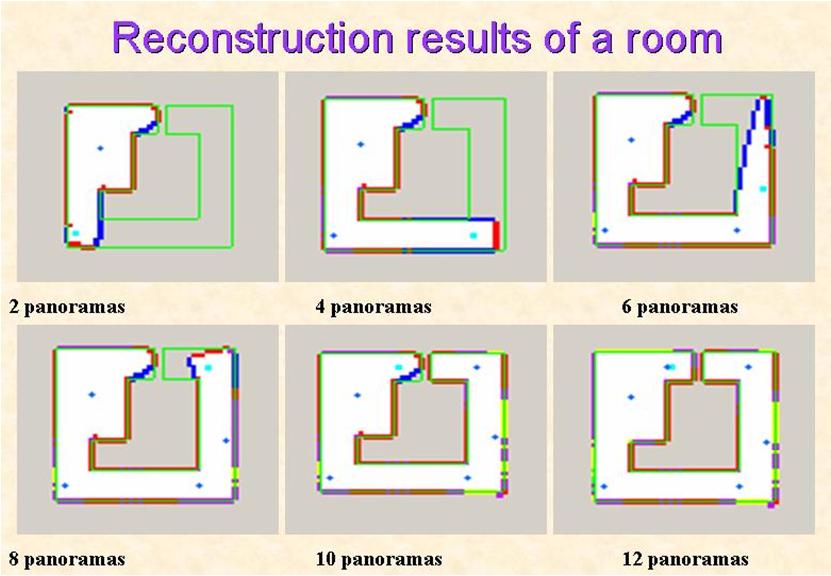
Finding the Next Best View in 3D Scene Reconstruction using Panorama Arrays
We presents a 3D modeling system for scene reconstruction by capturing a set of panoramas, called a panorama array. An initial volume containing a target scene is divided into fixed sized cubes, called voxels. The projections of each voxel on every panorama are efficiently determined using an index coloring method. By carving away voxels failing the color consistency test, the structure of a scene is unveiled gradually. In addition, we design a smart sampling strategy that can find out the next best view position for new panorama acquiring without knowing the layout of a scene in advance. The objective is to reconstruct the maximum regions of a scene using the minimum number of panoramas. The reconstructed scenes and the panorama arrays can create a virtual space in that users can move freely with six degrees of freedom.