支援行動資訊管理之主動式資料複製演算法
摘要
資料複製計畫 (data replication scheme) 是決定分散式網路系統中資料項
(data object) 的放置數目 (replication level) 及放置位置 (replication placement)
的演算法。其主要目標是降低網路傳輸成本,並在存取效率與更新成本之間取得一個最佳的平衡。傳統上為有線網路而設計的資料複製計畫採靜態方法
(static replication),也就是資料項存放的數目及位置,在系統設定之時即固定下來,任何更動皆需要人為的重新設定。因為使用者的移動特性,靜態資料複製方法並不適用於行動計算環境。動態資料複製計畫
(dynamic replication scheme) 演算法的基礎是建立在動態地統計使用者的存取模式及遵照資料複製的一致性更新協定來計算網路傳輸成本,以決定資料項的放置與否。我們提出一個適用於行動計算環境的動態資料複製方法,稱之為「主動式資料複製演算法」(active
replication scheme)。我們特別針對行動計算的特性,利用使用者識別檔 (user
profile) 來記錄個人行程表和存取行為,以更精確的成本計算方式,來決定資料項的分佈,它可以有效地降低網路傳輸成本、加快反應時間、並提高各區域伺服器資料存取的就地可及性
(local availability)。
關鍵字: 行動計算,動態資料複製,存取趨勢,使用者識別檔
1. 簡介
所謂資料複製係指將相同內容的資料項分開儲存在分散式網路中不同的節點上[8]。資料項的複製數目及存放位置隨著網路上各地方使用者需求不同而不同。數目愈多,存取效率就愈為提昇,但系統所付出的管理維護成本也相對提高。而資料複製計畫就是決定資料項的複製數目及存放位置的演算法。可以是針對每一個資料項,決定複製數目及存放位置;或是針對某一節點,決定要不要放一份該資料項的複製。其設計主旨在於如何提昇存取效率和降低網路傳輸成本[13]。傳統的資料複製計畫是系統設計者在系統運作之前靜態加以指定,若要更改也是手動更改。這種方式不盡理想,因為一個好的複製計畫應該要隨時配合系統情況動態地加以調整,稱為動態資料複製計畫[22]。
目前已被發展出來的動態資料複製計畫演算法都是建立在動態地統計使用者存取趨勢及遵照資料複製的一致性更新協定來計算網路傳輸成本,以決定資料項的放置與否[1,10,15,20,21]。依這些演算法的本質來看,都相信使用者存取模式具有一些性質,像是存取資料範圍的區域性
(locality) 和習慣性。如果存取趨勢改變,顯然必須等待存取行為發生一段時間過後經過統計和計算,資料複製分佈模態才會調整成適當因應的分佈狀態,因此我們認為這樣子的反應方式是被動的
(passive)。從另一種觀點來思考,使用者的存取習慣特質,經常是依使用者所從事的工作而發生,並且跟著使用者移動;而系統中存取趨勢改變的主要原因,也是使用者所從事工作的改變以及使用者的移動。在傳統有線網路系統中因為使用者不易移動所以存取趨勢常隨著地理位置而固定,所以靜態或被動式的動態複製計畫還足以適用。但是在行動計算環境中,使用者移動的現象必然是自由而普遍的,傳統方法不再適用[3,11,12,17]。我們針對行動計算的特性,利用使用者識別檔來記錄其存取資訊
(access information),設計出一個主動式的動態資料複製計畫演算法,更精確地計算網路傳輸成本,以決定資料項複製的分佈。同時透過合理的宣告和預測方式,不待存取行為的發生,就主動將使用者所需的資訊,配合其移動特性而複製,大幅提昇資料擷取的就地可及度和反應時間。
我們用 C 程式來模擬行動計算環境下使用者的移動和存取的各種情況,並且使用五種資料複製計畫的演算法進行資料複製方法的比較實驗
: (1)各資料項不作複製,只有分散式的存放。(2)靜態複製。(3)我們的主動式資料複製計畫演算法。(4)動態資料配置
(Dynamic Data Allocation, D.D.A.) 演算法 [15]。(5)適應型資料複製
(Adaptive Data Replication, A.D.R.) 演算法 [21] 。程式中統計出這五種演算法個別所造成的每次存取平均網路傳輸成本
(transmission cost)、回應時間 (response time)、各節點儲存資料項的平均就地可及度。模擬結果顯示,五種演算法優劣順序大致為
(3)、(5)、(4)、(2)、(1),顯示主動式資料複製演算法的效能頗佳。
本文架構如下:第一節介紹我們的研究動機、目的和成果。第二節略述在資料複製計畫這個研究領域曾經被發表出的構想、模型、應用和演算法。第三節詳細敘述我們所提出的主動式資料複製計畫演算法,包括各組成單元和系統架構。第四節介紹我們如何以
C 程式進行模擬行動計算環境的實驗,來評估我們演算法的效能,並與其他演算法相比較。同時針對實作所可能遭遇到的問題作一番討論。第五節則是對於整體的研究成果作一個結論,並探討未來可能的發展方向。
2. 相關研究
動態資料複製計畫演算法是建立在動態地統計使用者的讀寫趨勢及遵照資料複製的一致性更新協定來計算成本,以決定資料項的放置與否。資料複製的成本要如何計算呢﹖假設
Rj 表示在某個伺服器上的使用者平均每單位時間讀取資料項 Oj
的次數,Wj
表示在整個分散式系統中的使用者平均每單位時間寫入資料項
Oj 的次數,a 表示每次在本地伺服器上能夠讀取到一個資料項,比起到遠地主機讀取一個資料項所能節省的成本,b
表示每次更新一份資料項複製所必須花費的成本。則 (a * Rj) 表示若該伺服器上有一份
Oj 的複製,每單位時間總共可以節省的成本﹔(b * Wj)
表示每單位時間總共必須多花費的成本。如果 (a * Rj) > (b * Wj),表示放一份
Oj 的複製在該伺服器上是有利的;反之如果 (a * Rj)
< (b * Wj),表示放一份 Oj 的複製在該伺服器上是不利的。這種成本計算就是動態複製計畫演算法的基礎
[15,
18]。如果把存取的成本 a 和 b 都設定成網路距離 d,則用 Rj 和
Wj 兩者作比較即可[21]。
主要的動態資料複製計畫的演算法大致可分為下列兩類:(1)讀寫次數統計法:這種演算法調整資料複製分佈的方法是利用統計某節點對該資料項平均每一單位時間讀的次數,和整個系統對該資料項平均每一單位時間寫的次數,來決定若有該資料項的複製放在該節點時可以節省的成本和所必須多付出一致性的維護成本。若前者大於後者,則將複製存放之;若後者大於前者,則不將複製存放在該節點。而調整的時機則是每隔一段時間,或在每一次發生資料存取事件的時候
[15,
18]。(2)鄰接式資料複製法:這種方式大致和上述方式相似,但它多加限制一個條件,就是同一資料項在網路上所有的複製都必須是鄰接的。此鄰接式限制的好處是可以減少資料作一致性維護更新時網路傳輸成本,所以它只考慮該複製群邊緣節點和週遭鄰接的節點對該資料項的讀寫次數和複製存不存放
[21]。即使是動態的改變資料複製結構,其調整時機仍必須等待存取行為發生一段時間過後,經過統計和計算才能進行。這在變動性高的行動計算環境中,仍顯得機動性不足。我們設計的主動式資料複製計畫演算法,能更精確地計算網路傳輸成本,並主動調整資料項複製的分佈。
3. 主動式資料複製計畫
各種動態複製計畫幾乎都是以統計過去讀寫次數為決定存不存放複製的依據,其基本信念都是認為使用者的存取模式具有一些固定的特性,包括存取資料範圍的區域性和習慣性。我們基於同樣的信念,在行動計算環境下作更精確的設計,加強下列三項特色:(1)讓使用者的特性徹底跟著使用者:有關資料項存取的歷史記錄不只是被記錄於區域的主機上,還必須能夠隨著使用者變遷而變化。達成這種理想的方式就是利用使用者的識別檔來記錄其存取資訊,其詳細運作方式將詳述於後。(2)加強對於未來存取狀況預測的準確性:系統動態地統計使用者的存取狀況無非就是為了把這些統計資訊當作預測未來可能狀況的依據。我們在預測未來的這個觀點上再做更有力的設計。利用使用者自行於事前宣告的行程表
(schedule) 來預測使用者的存取動向,而這個行程表也是被記錄於識別檔裡,其詳細結構與格式將詳述於後。(3)加強對於應用過去存取狀況統計的準確性:我們設計的方式是在應用一個使用者的存取記錄之前,先經過合理的篩選。考慮一個使用者的存取記錄,在不同的情況下,我們會選用使用者目前正在使用或是將會用到的資料項的存取記錄。目前不會用到的其它資料項,其存取記錄則不列入演算法的考慮之內,這就是我們提出的「開放資料項」(open
object) 的觀念,其詳細定義將詳述於後。這一節將敘述主動式資料複製計畫的運作環境、所需的資料結構、和演算法。
3.1 行動計算環境
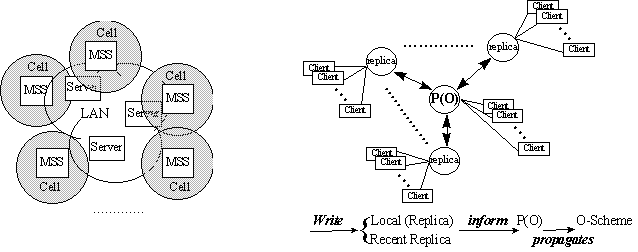
一個區域性的行動計算環境如 (圖一)
所示,包括下列各單元:
(1) LAN:區域性有線網路,也是我們複製處理系統運作的範圍
(2) Server:在當地的主機,是區域網路中儲存資料的伺服器,被視為網路上的節點。
(3) MSS (Mobile Support Station):無線通訊基地台,也是區域性的伺服器
(4) Cell:一個 MSS 的無線通訊範圍。
(5) MH (Mobile Host):個人行動式無線通訊主機,被視為使用者。
在行動計算環境中,使用者必須以自己的帳號登入系統,並且可以自由遊走於 Cell
與 Cell 之間。當一個使用者從某一個 Cell 移動到另一個 Cell 時,相對應的兩個
MSS 會作切換 (hand off) 的動作。也就是說,每個 MSS 可以知道使用者的進入和離開。此外,為了識別不同的使用者和記錄位置資訊,每個使用者都有一個識別檔動態存在於有線區域網路的節點之中,這種使用者識別檔是行動計算環境中不可或缺的資料結構。
|
|
(圖一) 行動計算環境
(圖二) Primary Copy Model
|
3.2 Primary Copy Model
我們採用 primary copy model
(圖二) 為一致性維護架構:針對某一資料項 (O) 的所有複製 (O-scheme) 中選出一份當作
primary copy (P(O))。P(O) 所在的伺服器必須掌握系統中所有與 O 有關的資訊,包括其複製所在位置,以及系統中所有使用者對
O 的 write 次數。而其複製所在的伺服器也必須知道 P(O) 的位置。任何一份複製在發生
write 動作時,必先通知 P(O),P(O) 再負責通知 O-scheme 的所有複製作更新,以維護各複製版本的一致性。此外,在選擇使用何種資料複製更新協定方面,我們是先以最基本的
read-one-write-all 協定作考慮,也就是 read 可以讀任何一份複製,write 則必須待
O-scheme 的所有複製皆作更新才算完成,其成本與 O-scheme 在分散式系統中所形成的樹
(tree) 的大小成正比。其它更精妙的更新協定,本系統仍可採用,但其詳細內容及演算法並不在本文的討論範圍之內。
3.3 系統資訊
在說明我們的演算法之前,我們必須先介紹演算法運作時所必須使用到的各種系統資訊。我們先定義下列名詞及符號,以方便說明系統資訊及演算法:
-
O1、O2、....、Ok 代表系統內所有的資料項共
k 個。
-
Cell1、Cell2、....、Celln 代表系統內所有的基地台通訊範圍共
n 個。
-
Site1、Site2、....、Siten 代表系統內所有的基地台伺服器共
n 個,也是系統有線網路上的節點。
-
User1、User2、....、Userm 代表系統內所有的行動式使用者共
m 個。
-
Prof1、Prof2、....、Profm 代表系統內行動使用者的識別檔共
m 個。
-
Schd1、Schd2、...、Schdm 代表系統內行動使用者在其識別檔內所宣告的行程表共
m 個。
3.3.1 記錄於識別檔內的存取資訊
在我們的演算法中,有一個非常重要的環節就是充分利用使用者識別檔來記錄其存取資訊,包括:使用者的行程表、讀/寫的歷史記錄
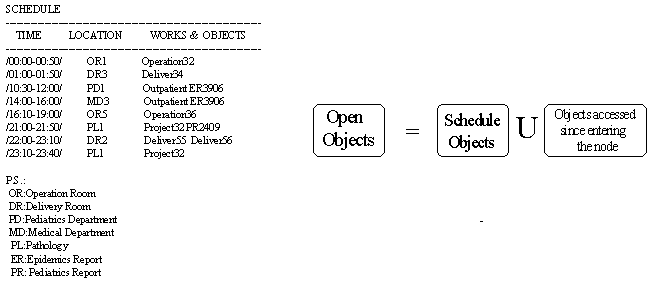
(read/write history)、以及目前的開放資料項 (open objects)。使用者事先宣告自己的行程和工作並記錄於識別檔內稱為使用者行程表。其基本內容為:在什麼時段內、位置將會在哪裡、將從事什麼工作或需要什麼資料項。例如:在醫院系統中,第五十一號使用者,在時段
01:00 ~ 05:00 時,會到內科門診去主持門診,需要所有已預約看診病患的病歷,以及最近三個月的流行病的追蹤資料。系統必須有相關的應用程式提供使用者一些有關地點、工作、資料的選單來製訂其行程表,並以文字檔的形式展現出行程表的內容以供使用者查閱。(圖三)
是一個文字檔行程表的例子。諸如資料的規劃和分類、地點、工作、各工作所需的資料項,都是由系統管理者靜態手動制定。當一個區域伺服器在讀取使用者行程表時必須透過這些制定來判定行程表中所宣告的地點是網路上的哪個節點,所宣告的工作需要哪些資料項,再將這些資料項和使用者在行程表中所特別指明的資料作聯集,而得到該使用者完整的存取需求。我們再定義下列名詞:(1)遵照行程的使用者
(on schedule):當某個使用者在某個時間地點,而該時間地點符合這個使用者在行程表中的宣告。(2)非遵照行程的使用者
(off schedule):當某個使用者在某個時間地點,而該時間地點不符合這個使用者在行程表中的宣告。
讀寫的歷史記錄是一個使用者對於個別資料項的讀取及寫入次數或頻率。有鑒於一個使用者並不是隨時需要存取系統內全部的資料項,在某個地點的某一段時間,所存取的資料項目有限。因此我們定義一個使用者的「開放資料項」為:該使用者位在某一區域時,若是屬於遵照行程的使用者,則行程表內這段行程中所宣告的需求資料項;以及,不論這個使用者是不是遵照行程,從進入目前所在地點開始到現在,其存取過的資料項。它的意義代表一個使用者目前的存取範圍;並且因為有些開放資料項是在行程表內所宣告,所以也包含了提前預測使用者存取動向的意義。(圖四)
表示了某個使用者的「開放資料項」的定義。
|
|
(圖三) 文字檔的使用者行程表
(圖四) 使用者個人現在的開放資料項
|
3.3.2 記錄於伺服器內的存取資訊
在區域伺服器內存有下列與複製管理有關的元件:(1)資料項的複製。(2)複製管理系統控制單元。(3)區域存取資訊。其中複製管理系統控制單元就是我們主動式資料複製計畫演算法的程式碼,該演算法詳述於
3.5 節。而所謂的區域存取資訊則是包含該區域使用者們的識別檔,以及記錄哪一些是行程內使用者,以及記錄每一個資料項目前的「區域被開放讀取的數據」(local_open_read)。何謂「區域被開放讀取的數據」呢﹖若一個資料項是某個使用者現在的「開放資料項」,則我們稱這個資料項被這個使用者打開
(open)。一個資料項的「區域被開放讀取的數據」是目前所有在該區域內打開這個資料項的使用者們,對這個資料項讀取的歷史記錄總和。顯然這個記錄是動態改變的,它在邏輯上是一個提供區域伺服器查詢的表格。
P(O) 所在的伺服器內除了記錄
O-scheme 的成員之外,還必須記錄該資料項 O 的「全域被開放寫入的數據」(global_open_write),定義為:目前所有在分散式系統全域內打開這個資料項的使用者們,對這個資料項寫入的歷史記錄總和。顯然這個記錄也是動態改變的,而且是從所有使用者的識別檔內所記錄的寫的歷史記錄加總而得。它在邏輯上也是一個提供區域伺服器查詢的表格。
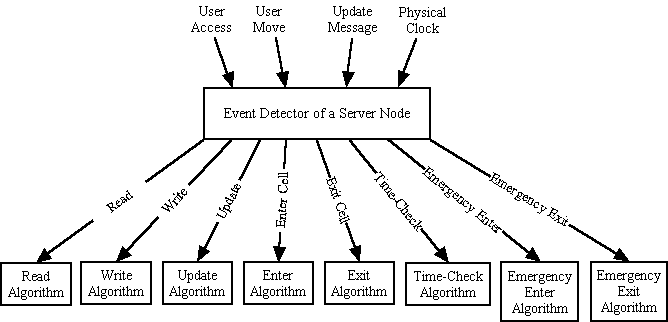
3.4 事件
主動式複製管理系統是以事件驅動的方式來運作。所謂事件
(event) 就是系統事先定義會在系統內發生的某種特定情況,這種情況必須是系統能偵測到的;而該情況一發生時系統必須去作因應處理,稱為事件驅動。事件有下列六種:(1)
讀取事件 (read event):某個使用者讀取某個資料項。(2) 寫入事件 (write event):某個使用者寫入某個資料項。(3)
更新事件 (update event):某個資料項複製被更新。(4) 進入事件 (enter event):某個使用者進入某個
cell。(5) 離開事件 (exit event):某個使用者離開某個 cell。(6) 固定時間檢查事件
(time-check event):每個區域伺服器會每隔一段固定時間作例行性的資料複製管理檢查。(7)
緊急事件 (emergency event):其他由系統管理者所定義必須即時處理的緊急事件。
3.5 緊急資料項
為了加強我們演算法的有效性,可以讓使用者在行程表內定義緊急資料項
(emergency object),用以表示該資料項在該行程時立刻被需要;若該行程一旦發生時,我們的資料複製管理系統立刻無條件給予複製支援。(圖五)
表示在一個使用者行程表內定義緊急資料項的例子。如果系統要處理緊急資料項,則區域伺服器內的存取資訊就必須再多增加一項,紀錄每個資料項目前在該區域內「被宣告是緊急資料項的計數」(local_emergency_counter),意思是該資料項在該區域內被多少個行程內的使用者宣告為緊急資料項。例如目前在第二十區域,共有十八個行程內的使用者將第四十資料項宣告為緊急資料項,則該區域所記錄的第四十資料項「被宣告是緊急資料項的計數」值就等於18。
|
|
(圖五) 包含緊急資料項宣告的使用者行程表
(圖六) 網路距離
|
3.6 網路傳輸成本計算
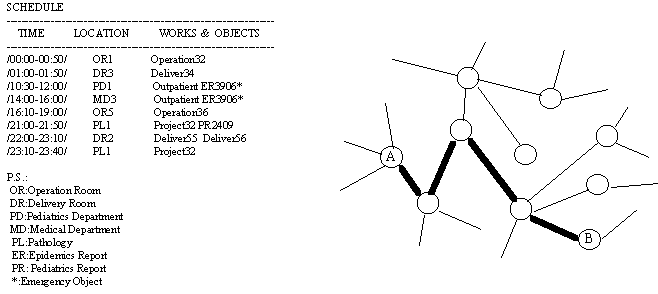
主動式資料複製演算法的成本分析模式和前述的相關研究中各個演算法相似,我們把複製放置的節省成本和多付出更新成本做比較,以判斷複製是否放置。我們的成本分析模式是針對網路傳輸成本加以考慮,把網路上相鄰的節點間每一次的要求和回覆設定其成本等於
1;而所謂的網路距離,是指傳輸路徑上所經過的邊的數目。舉例如 (圖六):若節點A到節點B的傳輸路徑上共經過四個邊,則稱節點
A 到節點 B 的網路距離為4,若節點 A 到節點 B 之間有一次資料存取發生,其網路傳輸成本也是
4。所以一次本地讀取比遠地讀取節省成本 d,d 為兩者網路距離;同理多更新一份複製一次所多耗費的成本也是
d。
假設某節點對一個資料項 Oj
的開放讀取平均是每單位時間 local_open_readj 次,而 Oj
的全域被開放寫入平均是每單位時間 global_open_writej 次。將存有
Oj 的一份複製的情況,和沒有 Oj 複製的情況相比較,前者比後者每單位時間總共節省成本是
(local_open_readj * d),總共多花費的更新成本是 (global_open_writej
* d)。當 (local_open_readj * d) >= (global_open_writej
* d) 時,也就是 (local_open_readj) >= (global_open_writej)
時,表示本地伺服器存有一份 Oj 的複製是有利的。當 (local_open_readj
* d) < (global_open_writej * d) 時,也就是 (local_open_readj)
< (global_open_writej) 時,表示本地伺服器存有一份 Oj
的複製是不利的。這就是主動式資料複製演算法的成本計算基礎。
3.7 演算法
我們以事件驅動、分散式處理的形式來設計主動式資料複製演算法,它們常駐在每個伺服器中,包括下列個組成單元:(1)讀取演算法
(read algorithm) 。(2)寫入演算法 (write algorithm) 。(3)複製更新演算法
(update algorithm) 。(4)進入演算法 (enter algorithm) 。(5)離開演算法 (exit
algorithm) 。(6)固定時間檢查演算法 (time-check algorithm) 。(7)緊急事件演算法
(emergency enter & exit algorithm) 。(圖七) 表示出常駐在各區域伺服器中事件驅動形式的主動式資料複製演算法架構。
|
|
(圖七) 常駐在區域伺服器中事件驅動形式的主動式演算法架構圖
|
當某個節點上發生資料項讀取事件
Useri 讀取 Oj 的時候,讀取演算法在當地的伺服器被驅動執行:首先是檢查
Useri 識別檔 Profi 中所記錄的開放資料項,若 Oj
還不是 Useri 目前的開放資料項,則將 Oj 打開,設定成
Useri 的開放資料項,並從 Profi 中找出對 Oj 讀的歷史記錄
(readij),加進當地主機所記錄 Oj
目前在該區域的「被開放讀取的數據」之中,同樣從
Profi 中找出對 Oj 寫的歷史記錄 (writeij),傳給
P( Oj ) 所在伺服器,加進 Oj 的「全域被開放寫入的數據」之中。接著是將
readij
加 1,並且把 Oj 在該區域的「被開放讀取的數據」加 1。然後檢查
Oj 是否已經有一份複製存在於當地伺服器,若還沒有,則針對是否複製
Oj 作成本計算。若計算的結果是有利的,則決定在當地伺服器儲存一份
Oj 的複製,並通知 P( Oj )。(圖八)是這個讀取演算法。
當某個節點上發生資料項寫入事件
Useri 寫入 Oj 的時候,寫入演算法在當地的伺服器被驅動執行:首先是檢查
Useri 識別檔 Profi 中所記錄的開放資料項,若 Oj
還不是
Useri 目前的開放資料項,則將 Oj 打開,設定成 Useri
的開放資料項,並從 Profi 中找出 readij,加進當地主機所記錄
Oj 在該區域的「被開放讀取的數據」之中,同樣地從 Profi
中找出 writeij,傳給 P( Oj
)
所在伺服器,加進 Oj 的「全域被開放寫入的數據」之中。接著是將
writeij
加 1,並且把 Oj 的「全域被開放寫入的數據」加 1。(圖九)是這個寫入演算法。
當某個節點上發生資料項 Oj
的複製更新事件的時候,更新演算法在當地的伺服器被驅動執行:針對是否繼續把
Oj
的複製儲存在當地伺服器作成本計算,若計算的結果是不利的,而且
Oj
在當地伺服器並不是一個緊急資料項,則決定放棄在當地伺服器儲存一份
Oj 的複製,並通知 P( Oj )。(圖十)是這個更新演算法。
當某個節點 Sitej 上發生使用者
Useri 進入 Cellj 的時候,進入演算法在 Sitej
上被驅動執行:第一步是檢查
Useri 識別檔 Profi 中所宣告的行程表 Schdi,若這個時間地點是
Schdi 中所宣告的行程,則將該行程所需的資料項打開,設定成 Useri
目前的開放資料項,並從 Profi 中找出 readij,加進當地主機所記錄資料項在該區域的「被開放讀取的數據」之中。同樣地從
Profi 中找出 writeij,傳給它們各
P(O) 所在伺服器,加進它們的「全域被開放寫入的數據」之中。再從 Schdi
中得知該行程所宣告的緊急資料項,將當地主機所記錄的有關這些緊急資料項之「被宣告是緊急資料項的計數」值加上
1。第二步是針對是否複製這些資料項作成本計算,若該資料項還沒有複製存在於當地伺服器,而且,計算的結果是有利的,或是其「被宣告是緊急資料項的計數」的值大於
0,則決定在當地存放一份複製,並通知其個別的 P(O) 。(圖十一)說明了這個進入演算法。
當某個節點 Sitej 上發生使用者
Useri 從 Cellj 離開的時候,離開演算法在 Sitej
上被驅動執行:首先是從
Useri 的識別檔 Profi 中得知 Useri 在當地所有的開放資料項與緊急資料項,將當地主機所記錄這些緊急資料項「被宣告是緊急資料項的計數」的值減去
1,並從開放資料項的「被開放讀取的數據」之中扣除 Useri 對這些開放資料項讀的歷史記錄,並且通知它們各
P(O) 所在伺服器。同樣從 P(O) 所在主機所記錄的有關它們的「全域被開放寫入的數據」之中扣除
Useri 對這些開放資料項寫的歷史記錄,然後當地伺服器會針對這些開放資料項重新評估是否在當地放置他們的複製。如果某個資料項在當地「被宣告是緊急資料項的計數」大於零,則仍決定繼續放置其複製;如果某個資料項在當地「被宣告是緊急資料項的計數」等於零,則作成本計算,不論其原來是否有複製放置於當地主機。若計算的結果是有利的就決定放置,並通知其個別的
P(O);若計算的結果是不利的就決定不要放置,並通知其個別的 P(O)。接著將這些開放資料項的記錄通通從
Profi 中清除。(圖十二)說明了這個離開演算法。
每個節點都會每隔一段固定時間對於該地區的所有使用者作一遍檢查。檢查的目的是察看區域內是否有行程內的使用者變成非行程內的使用者,或是有非行程內的使用者變成行程內的使用者。這兩種情況系統通通視同該使用者先離開該節點再重新進入該節點,也就是對那些使用者先執行離開演算法,再重新執行進入演算法。(圖十三)說明了這個固定時間檢查演算法。
系統管理者會定義一些系統可以偵測發生及結束的緊急事件,以及這些緊急事件所需存取的資料項,一旦這些緊急事件發生時,我們的複製管理系統立刻按照如
(圖十四) 所示的進入緊急事件的演算法給予複製支援;緊急事件結束後,則按照如
(圖十五) 所示的離開緊急事件的演算法來考慮複製是否繼續留置。
|
READ Algorithm
|
WRITE Algorithm
|
When (the event Useri reads
Oj
occurs)
{
if (Oj is not
an open object of Useri )
{
Add
Oj to the list of open objects of Useri ;
local_open_readj
:= local_open_readj + readij ;
global_open_writej
:=
global_open_writej + writeij ;
}
readij := readij
+ 1;
local_open_readj :=
local_open_readj + 1;
if (no local replica of
Oj exist) AND
(local_open_readj
>= global_open_writej)
Allocate
a replica of Oj and inform P(Oj);
} |
When (the event Useri writes
Oj
occurs)
{
if (Oj is not
an open object of Useri )
{
Add
Oj to the list of open objects of Useri ;
local_open_readj
:= local_open_readj + readij ;
global_open_writej
:=
global_open_writej + writeij ;
}
writeij := writeij
+ 1;
global_open_writej
:= global_open_writej + 1;
} |
|
(圖八) 讀取演算法
|
(圖九) 寫入演算法
|
|
Update Algorithm
|
ENTER Algorithm
|
When (an update to a replica of
Oj occurs)
{
if (local_emergency_counterj
=
0)
AND
(local_open_readj
< global_open_writej)
Discard
the replica of Oj and inform P(Oj);
} |
When (the event that
Useri enters the cell occurs)
{
if
(Useri is on schedule)
{
for all Oj
required in Schdi
{
Add Oj to the list of open objects of Useri
;
local_open_readj
:=
local_open_readj + readij ;
global_open_writej
:=
global_open_writej + writeij ;
if
(Oj is an emergency object)
local_emergency_counterj :=
local_emergency_counterj + 1;
if
(no local replica of Oj exist) AND
(
(local_open_readj >= global_open_writej)
OR (local_emergency_counterj > 0) )
Allocate a replica of Oj and inform P(Oj);
}
}
} |
|
(圖十) 更新演算法
|
(圖十一) 進入演算法
|
|
EXIT Algorithm
|
TIME-CHECK Algorithm
|
When (the event that Useri exits the cell occurs)
{
for all open objects Oj of Useri
{
Remove Oj
from the open objects of Useri ;
local_open_readj
:= local_open_readj - readij ;
global_open_writej
:=
global_open_writej - writeij ;
if (Oj
is an emergency object requested)
local_emergency_counterj :=
local_emergency_counterj - 1;
if (Oj
has a replica in the site) AND
(local_emergency_counterj
= 0) AND
(local_open_readj
< global_open_writej)
Discard
the replica of Oj and inform P(Oj) ;
}
} |
When (a local time-check event occurs)
{
for each local Useri
{
if (the on/off schedule
status has changed)
{
call
EXIT
Algorithm for Useri ;
call
ENTER
Algorithm for Useri ;
}
}
} |
|
(圖十二) 離開演算法
|
(圖十三) 固定時間檢查演算法
|
|
EMERGENCY-ENTER Algorithm
|
EMERGENCY-EXIT Algorithm
|
When (an emergency event occurs)
{
for all Oj required in the emergency
event
{
local_emergency_counterj
:=
local_emergency_counterj + 1;
if (no local replica
of Oj exist)
Allocate a replica of Oj and inform P(Oj);
}
} |
When (an emergency event is over)
{
for all Oj required in the emergency
event
{
local_emergency_counterj
:=
local_emergency_counterj - 1;
if (local_emergency_counterj
= 0) AND
(local_open_readj
< global_open_writej)
Discard the replica of Oj and inform P(Oj);
}
} |
|
(圖十四) 緊急事件進入演算法
|
(圖十五) 緊急事件結束演算法
|
4. 效能評估
我們採用的效能評估方式,是以
C 程式模擬行動計算環境以及使用者存取和移動行為,並且模擬以下演算法資料複製系統的運作:(1)不作複製,只有固定分散存放。(2)靜態指定方式複製。(3)我們的主動式資料複製計畫演算法。(4)動態資料配置演算法[15]。(5)適應型資料複製演算法[21]。然後在程式中用三種統計數據來衡量演算法的效能:(1)每次存取平均網路傳輸成本;(2)每次讀取平均回應時間;(3)各節點所存放資料的平均區域可及度
(local availability)。回應時間的計算是以網路距離的遠近為依據,所以讀取平均回應時間也代表著讀取平均網路距離。區域可及度是指在一個節點可就地讀取到資料的比例。例如,共讀取資料
100 次,其中 87 次可在本地伺服器找到,其餘 13 次須到遠端讀取,則該節點資料的區域可及度等於
87%。
使用者行為分成存取行為和移動行為兩種;存取行為是指使用者存取資料項的範圍和習慣,而移動行為是指使用者地理位置移動的範圍和習慣。我們將系統中所有的節點、資料項、使用者分類。每個使用者都對應到某個存取類別以及位置類別。一個使用者的存取類別表示其存取資料項的範圍,位置類別表示其地理位置移動的範圍。存取類別代表不同類別的使用者存取資料項範圍的不同,例如在一個學校系統中學生、老師、行政人員等,各有各的習慣性存取資料項範圍。位置類別代表不同類別的使用者地理位置移動範圍的不同,例如在一個醫院系統中外科、內科、婦產科、行政人員等,各有各的習慣性地理位置移動範圍。各類別之間並不一定互斥。屬於同一類別的人員其存取和移動習慣也不全然相同。我們用下列可操控變因來模擬一個使用者的行為特色:
(1) ACCESS CLASS (2) LOCATION CLASS (3) STAY_IN_CLASS (4) ACCESS_IN_CLASS
(5) WRITE_AFTER_READ (6) FOLLOW_SCHEDULE (7) EMERGENCY。分別於下列各小節中敘述。
節點兩兩之間的網路傳輸成本,是以
All Pairs Shortest Path 演算法 [2] 算出。所有資料項在系統中的初始分佈是參考使用者所屬存取類別和位置類別的對應關係,在某個位置類別的節點上,存放著屬於該類別的使用者常存取的資料項。模擬系統運作的方式,是以每個模擬單位時間
(十分鐘) 為迴圈進行,在每個單位時間的迴圈之中,讀取每一個使用者的識別檔,從所記錄的行為變因和行程表來決定他的地點和存取資料項,然後針對前述五種複製計劃所決定的資料分佈,分別計算存取成本,統計其回應時間和區域可及度。
4.1 以使用者移動性 (STAY_IN_CLASS) 為操作變因
我們以使用者移動性 (STAY_IN_CLASS
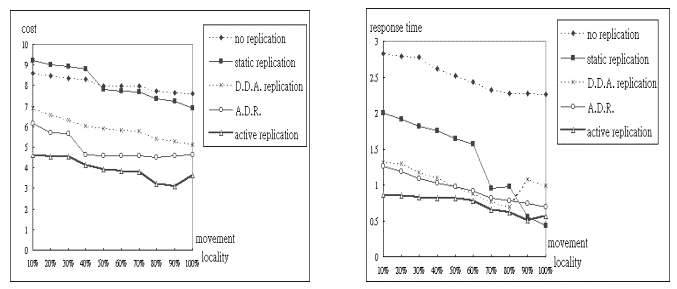
= 10% ~ 100%) 為操作變因 (亦稱為 movement locality),觀察其變化對演算法效能的影響。由
(圖十六) 可知當 movement locality 越大,也就是移動性越小,平均每次存取的成本也就越低。原因是資料項複製的分佈範圍集中,導致傳輸距離的縮短,以及一致性更新成本的降低。五種演算法的優劣依序是
active replication、A.D.R.、D.D.A.、no replication 或是 static replication。其中
movement locality 在 50% 以上時 (亦即 50% 以上的機率在所屬 class 中進行存取動作),static
replication 靜態分佈的資料複製仍然有其好處,因此存取的成本比 no replication
低。Movement locality 在 40% 以下時,static replication 反而比 no replication
多出一致性更新的負擔,所以效果比 no replication 差。
由 (圖十七) 可知當 movement
locality 越大,平均每次讀取的回應時間也就越短。原因是使用者的移動的範圍越小,即使是遠地讀取的距離也越小。由
(圖十八) 可以知道除了active replication 之外,其他四種資料複製演算法當
movement locality 越大,平均每個節點的資料區域可及度也就越高,原因是使用者的移動範圍越小,資料複製分佈密度就越集中。而
active replication 演算法以行程表為依據作事先的預測,所以即使在 movement
locality 較小的情況,仍能維持高度的區域可及度。五種資料複製演算法的優劣依序大致是
active replication、D.D.A.、A.D.R.、static replication、 no replication。
|
| (圖十六) 各種資料複製計劃在使用者移動性變化時平均每次存取的成本 |
|
(圖十七) 各種資料複製計劃在使用者移動性變化時平均每次讀取的回應時間 |
|
|
(圖十八) 各種資料複製計劃在使用者移動
(圖十九) 各種資料複製計劃在使用者遵照
性變化時平均每次存取的區域可及度
其行程表機率變化時平均每次存取的成本
|
4.2 以使用者依循行程表的程度 (FOLLOW_SCHEDULE) 為操作變因
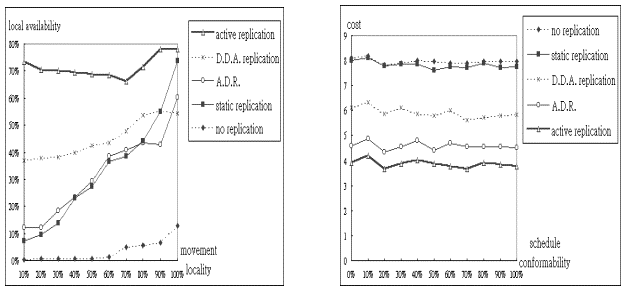
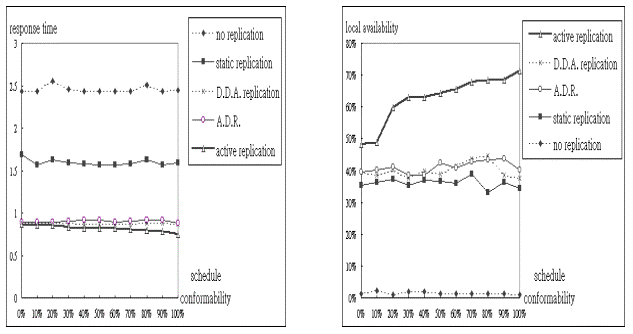
我們以使用者依循行程表的程度
(FOLLOW_SCHEDULE = 0% ~ 100%) 為操作變因 (又稱為 schedule conformability),觀察其變化對演算法效能的影響。由
(圖十九) 可以觀察出行程表對於存取成本沒有顯著的影響。即使是在我們的 active
replication 演算法中,其主要功能在於降低回應時間和提高資料的區域可及度,而非降低存取成本。但不論如何
active replication 演算法在存取成本方面仍舊表現得比其他四種演算法好。五種資料複製演算法的優劣依序是
active replication、A.D.R.、D.D.A.、static replication、no replication。另由
(圖二十) 與 (圖二十一) 可知除了 active replication 演算法之外,使用者是否依循其行程表動作對於其他四種演算法的讀取回應時間和區域可及度沒有顯著的影響,而
active replication 演算法則有隨著使用者遵照行程表機率越高而讀取回應時間越短以及區域可及度越大的趨勢,因為我們的演算法充分利用到使用者行程表對使用者的存取作事先的預測,可以主動把部分使用者將要讀取資料項的複製放在當地的區域伺服器。
|
| (圖二十) 各種資料複製計劃在使用者遵照其行程表機率變化時平均每次讀取的回應時間 |
|
(圖二十一) 各種資料複製計劃在使用者遵照其行程表機率變化時平均每次讀取的區域可及度 |
|
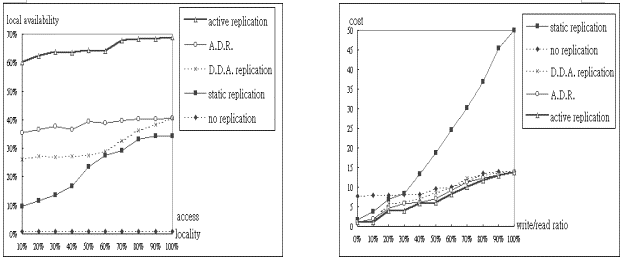
4.3 以使用者存取習慣性 (ACCESS_IN_CLASS) 為操作變因
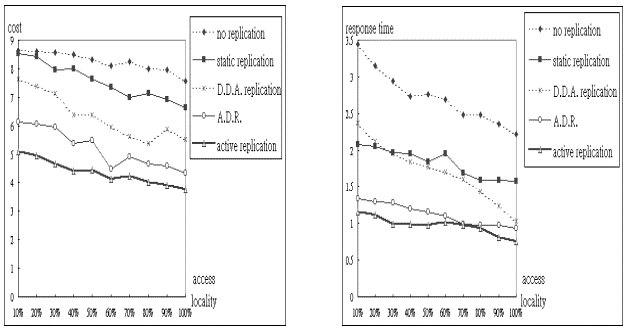
我們以使用者存取習慣性 (ACCESS_IN_CLASS
= 10% ~ 100%) 為操作變因 (又稱為 access locality),觀察其變化對演算法效能的影響。由
(圖二十二) 可知當使用者存取習慣性越固定,平均每次存取的成本也就越少。原因是各種資料複製演算法都是基於使用者的存取有習慣性為理念來設計的,即使是不作複製的
no replication 其資料的初始分佈也是按照使用者存取的習慣性和移動的地理區域來安排。若存取習慣性越不固定,各種演算法的效果就越差,優劣依序仍是
active replication、A.D.R.、D.D.A.、static replication、no replication。另由
(圖二十三) 和 (圖二十四) 可知當使用者存取習慣性越固定,平均每次讀取的回應時間越少,平均每個節點所儲存資料的區域可及度也越高,原因同上。
|
(圖二十二) 各種資料複製計劃在使用者存
(圖二十三) 各種資料複製計劃在使用者存
取習慣性變化時平均每次存取的成本
取習慣性變化時平均每次讀取的回應時間
|
|
(圖二十四) 各種資料複製計劃在使用者存
(圖二十五) 各種資料複製計劃在使用者寫
取習慣性變化時平均的區域可及度
讀比率變化時平均每次存取的成本
|
4.4 以寫讀比率 (WRITE/READ RATIO) 為操作變因
我們以寫讀比率 (WRITE/READ RATIO
= 0% ~ 100%) 為操作變因,觀察其變化對演算法效能的影響。由 (圖二十五) 可知當使用者寫入比率越大,平均每次存取的成本越高,原因是增加寫入及一致性更新的成本,以及複製數目減少而造成的遠地存取成本增加。五種演算法的優劣大致是
active replication、A.D.R.、D.D.A.、no replication、static replication。值得注意的是當寫讀比率為
0% 時,三種動態資料複製演算法幾乎達到使用者所移動到的各節點均遍佈複製的情況
(full replication),每次讀取幾乎都是本地讀取,三者的存取成本相近;當寫讀比率為
100% 時,三種動態資料複製演算法幾乎達到不作複製的情況,與 no replication
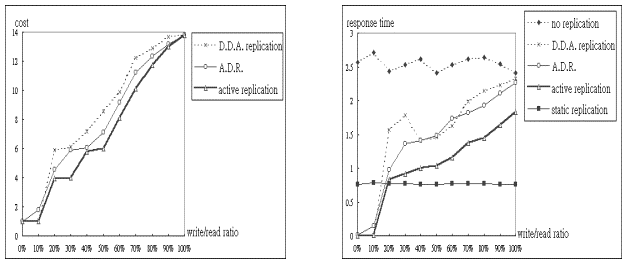
情況相同,四者的存取成本相近。(圖二十六) 是特別將三種動態資料複製演算法的數據作一個比較的曲線圖。由
(圖二十七) 可知除了no replication、static replication之外,三種動態資料複製演算法當使用者寫讀比率越大,平均每次讀取的回應時間也就越高,原因是寫入次數增多造成複製數目減少而造成遠地讀取次數增加。五種演算法的優劣大致是
static replication、active replication、A.D.R.、D.D.A.、no replication。但在現實系統的情況使用者寫讀比率幾乎都在
20% 以下,此時五種演算法的優劣則是 active replication、A.D.R.、D.D.A. 、static
replication、no replication。由 (圖二十八) 可知除了 no replication 與 static
replication 之外,三種動態資料複製演算法當使用者寫讀比率越大,平均每個節點所儲存資料項的區域可及度也就越低,原因同上。
|
(圖二十六) 三種動態資料複製計劃在使用
(圖二十七) 各種資料複製計劃在使用者寫
者寫讀比率變化時平均每次存取的成本
讀比率變化時平均每次存取的回應時間
|

|
(圖二十八) 各種資料複製計劃在使用者寫讀比率變化時平均區域可及度
|
4.5 實作規劃
實作我們的演算法需注意的問題有:(1)
使用者讀寫歷史記錄的資料量;(2) primary copy model 架構之下 P(O) 的選擇;(3)
資料複製數目的上下限;(4) 系統內各節點時間的一致性;以及 (5) 其他的成本計算模型。我們分別對這些問題及解決方法作討論。
使用者的讀寫歷史記錄存於識別檔中,若系統內資料項的數目非常多,可能造成讀寫歷史記錄的資料量會非常大,而大量資料被記錄於識別檔中的作法是不合理的。所幸使用者的存取模式具有相當的區域性和習慣性,我們可以使用動態資料結構來記錄該使用者存取資料的讀寫次數,達成有效節省儲存空間的目的。也可以採用限量工作集的方式來記錄,當該使用者存取資料項的數目超過限量時,則放棄記錄其中最久未發生存取的資料項,也就是只記錄代表著該使用者目前工作集的資料項。
P(O) 所在伺服器身負重任,必須維護
O-scheme 與該資料項的 global_open_write 記錄,並接受該資料項的寫入、執行一致性更新的通知、與回應查詢
global_open_write 的要求。這些資訊也必須在其他節點上做複製,當 P(O) 所在伺服器發生故障時,或因成本計算不利的緣故必須退出
O-scheme 時,O-scheme 的其他成員之間必須舉行選舉,以產生新的 P(O),接管相關的資訊與工作,使系統能繼續順利地運作。我們可以採用各種適合在分散式網路上運作的選舉演算法
[5]
來完成系統的實作。
在實作主動式資料複製系統時可以設定資料複製數目的上下限,原因是為了提高系統可用性和容錯性。為免單一資料發生故障時無法順利存取及修復,下限應不小於
2。設定資料複製數目上限的原因是考慮到系統的管理能力有限,以及避免造成一致性更新花費過大。至於上限要設定多少,隨著系統性質不同而異。
因為主動式資料複製系統查詢使用者行程表的方式是以時間為基準,所以有必要考慮各節點之間時鐘的一致性。但是各節點之間並不需要有很強的時間一致性。可以採用一些如
Cristians Algorithm [4]、The Berkeley Algorithm
[7]
等傳統的時間同步演算法 (clock synchronization algorithms) 來完成系統的實作。
我們在 3.6 節所敘述的成本計算方式係以網路距離為主要依據,與
A.D.R. 的成本計算方式相似。我們也可以採用其他的觀點或方式來計算成本,例如
D.D.A. 的成本計算方式,或是 [18] 中所敘述的無線個人通訊服務系統中的成本計算方式,或是配合系統本身的特性,來設定讀寫的成本,當作我們主動式資料複製系統中各個演算法計算成本的依據。
5. 結論與未來方向
傳統動態資料複製演算法,並沒有考慮到無線環境下使用者會自由移動的情況。我們充分利用行動計算環境的特性,設計出一個適合在該環境中運作的主動式資料複製計畫。我們的設計是以事件驅動為導向,承襲傳統動態資料複製演算法的網路傳輸成本計算方法,並加以改進,能夠在行動計算環境中有效地複製資料項,達到降低網路傳輸成本、減少回應時間、提高各節點所儲存資料的區域可及性的目的。此外,我們並列舉出有關實作這個資料複製系統可能面臨的問題並討論解決方法。
主動式資料複製計畫中有一個重要的作法是利用使用者所宣告的行程表來預測其存取動向。行程表內容是以宣告時間、地點、工作為主;系統必須將所宣告的工作轉換成需求的資料項,其轉換對應的方式除了藉由系統管理者靜態地以手動方式加以定義之外,未來我們希望能發展出一套動態決定的方式繼續將這部分加以改進。再更進一步的構想是,未來我們希望把行程表這部分加以改進,讓使用者不必宣告自己的行程表,而交給系統自動觀察出使用者的存取特性、判斷使用者的存取動向;系統可以動態觀察並記錄歸納一個使用者在某個時段內位在某個地方執行某個應用程式時通常會需要哪些資料項,而據以定出行程表。
參考文獻
-
Acharya, Swarup and Stanley B. Zdonik. An
Efficient Scheme for Dynamic Data Replication. Brown Univ CS Dept Tech
Reports: CS-93-43, 1993.
-
Aho, Alfred. V., John.E.Hopcraft, Jeffrey.D.Ullman. The Design and
Analysis of Computer Algorithms. Addison Wesley, 1974.
-
Badrinath, B.R. and T. Imielinski. Replication and Mobility.
Proc. of the 2nd Workshop on the Management of Replicated Data (WMRD-2),
1992, pp 9-12, Monterey, CA.
-
Christian, F. Probabilistic Clock Synchronization. Distributed
Computing, vol. 3,pp.146-158, 1989.
-
Garcia-Molina, H. Elections in a Distributed Computing System.
IEEE Trans. On Computers, vol. 31, pp.48-59, July 1982.
-
Guerraoui, R. and Andrew Schiper. Software-Based Replication for
Fault Tolerance. Computers and Artificial Intelligence 1997: 68-74.
-
Gusella, R., and Zatti,S. The Accuracy of the Clock Synchronization
Achieved by TEMPO in Berkeley UNIX 4.3BSD. IEEE Trans. On Software
Engineering, vol. 15, pp. 847-853, July 1989.
-
Helal, Abdelsalam A., Abdelsalam A. Heddaya, and Bharat B. Bhargava. Replication
Techniques in Distributed Systems. Kluwer Academic Publishers. 1996.
-
Hui-I Hsiao, David J. DeWitt. A Performance Study of Three High Available
Data Replication Strategies. Distributed and Parallel Databases 1(1):
53-80 (1993).
-
Y.Huang, O.Wolfson. A
Competitive Dynamic Data Replication Algorithm. IEEE Proc. of
9th International Conference on Data Engineering'93 , pp 310-317.
-
Y.Huang, O.Wolfson. Dynamic Allocation in Distributed System and
Mobile Computer. IEEE Proc. of 9th International Conference on VLDB'92
, pp 4-52.
-
Yixiu Huang, A. Prasad Sistla, Ouri Wolfson. Data Replication for
Mobile Computers. SIGMOD Conference 1994, pp 13-24.
-
San-Yih Hwang, Keith K. S. Lee, Y. H. Chin. Data Replication in a
Distributed System: A Performance Study. DEXA 1996: 708-717.
-
M.C.Little and D.L.McCue. Computing Replication Placement in Distributed
System. Appeared in the Proceedings of the IEEE 2nd Workshop on Replicated
Data, Monterey, November 1992, pp 58-61.
-
M.C.Little and D.L.McCue. The
Replica Management System: a Scheme for Flexible and Dynamic Replication.
Appeared in the Proceedings of the 2nd Workshop on Configurable Distributed
Systems, Pittsburgh, March ,1994.
-
M.C.Little and S.K.Shrivastava. Using Application Specific Knowledge
for Configuring Object Replicas. Proceedings of the IEEE 3th International
Conference on Configurable Distributed Systems, May, 1996.
-
Evaggelia Pitoura. A Replication Scheme to Support Weak Connectivity
in Mobile Information Systems. DEXA 1996: 510-520.
-
Narayanan Shivakumar, Jan Jannink and Jennifer Widom. Per-User
Profile Replication in Mobile Environment: Algorithms, Analysis, and Simulation
Results. MONET 2(2): 129-140, 1997.
-
Jeff Sidell, Paul M. Aoki, Adam Sah, Carl Staelin, Michael, Stonebraker
and Andrew Yu. Data
Replication in Mariposa. Department of Electrical Engr. and Computer
Science, University of California Berkeley.
-
Ouri Wolfson and Sushil Jajodia. An
Algorithm for Dynamic Data Distribution. Proceedings of the IEEE
2nd Workshop on Replicated Data, Monterey, November 1992.
-
Ouri Wolfson, Sushil Jajodia and Yixiu Huang. An
Adaptive Data Replication Algorithm. ACM Transactions on Database
Systems, Volume 22, Number 2, June, 1997, pages 255-314.
-
Ouri Wolfson, Sushil Jajodia. Distributed
Algorithms for Dynamic Replication of Data. PODS 1992: 149-163.